Pandas Notebook 1, ATM350 Spring 2023
Contents
Pandas Notebook 1, ATM350 Spring 2023¶
Here, we read in a text file that has climatological data compiled at the National Weather Service in Albany NY for 2022, previously downloaded and reformatted from the xmACIS2 climate data portal.
We will use the Pandas library to read and analyze the data. We will also use the Matplotlib package to visualize it.
Motivating Science Questions:¶
How can we analyze and display tabular climate data for a site?
What was the yearly trace of max/min temperatures for Albany, NY last year?
What was the most common 10-degree maximum temperature range for Albany, NY last year?
# import Pandas and Numpy, and use their conventional two-letter abbreviations when we
# use methods from these packages. Also, import matplotlib's plotting package, using its
# standard abbreviation.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Specify the location of the file that contains the climo data. Use the linux ls command to verify it exists.¶
Note that in a Jupyter notebook, we can simply use the ! directive to “call” a Linux command.¶
Also notice how we refer to a Python variable name when passing it to a Linux command line in this way … we enclose it in braces!¶
file = '/spare11/atm350/common/data/climo_alb_2022.csv'
! ls -l {file}
-rw-r--r-- 1 ktyle faculty 15242 Feb 20 19:40 /spare11/atm350/common/data/climo_alb_2022.csv
Use pandas’ read_csv method to open the file. Specify that the data is to be read in as strings (not integers nor floating points).¶
Once this call succeeds, it returns a Pandas Dataframe object which we reference as df¶
df = pd.read_csv(file, dtype='string')
By simply typing the name of the dataframe object, we can get some of its contents to be “pretty-printed” to the notebook!¶
df
| DATE | MAX | MIN | AVG | DEP | HDD | CDD | PCP | SNW | DPT | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-01 | 51 | 41 | 46.0 | 19.7 | 19 | 0 | 0.12 | 0.0 | 0 |
| 1 | 2022-01-02 | 49 | 23 | 36.0 | 9.9 | 29 | 0 | 0.07 | 0.2 | 0 |
| 2 | 2022-01-03 | 23 | 13 | 18.0 | -7.9 | 47 | 0 | T | T | T |
| 3 | 2022-01-04 | 29 | 10 | 19.5 | -6.2 | 45 | 0 | T | 0.1 | T |
| 4 | 2022-01-05 | 38 | 28 | 33.0 | 7.5 | 32 | 0 | 0.00 | 0.0 | T |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 360 | 2022-12-27 | 34 | 22 | 28.0 | 0.6 | 37 | 0 | 0.00 | 0.0 | T |
| 361 | 2022-12-28 | 41 | 22 | 31.5 | 4.3 | 33 | 0 | 0.00 | 0.0 | T |
| 362 | 2022-12-29 | 48 | 22 | 35.0 | 8.1 | 30 | 0 | 0.00 | 0.0 | T |
| 363 | 2022-12-30 | 57 | 43 | 50.0 | 23.3 | 15 | 0 | 0.00 | 0.0 | 0 |
| 364 | 2022-12-31 | 53 | 44 | 48.5 | 22.0 | 16 | 0 | 0.08 | 0.0 | 0 |
365 rows × 10 columns
Our dataframe has 365 rows (corresponding to all the days in the year 2022) and 10 columns that contain data. This is expressed by calling the shape attribute of the dataframe. The first number in the pair is the # of rows, while the second is the # of columns.¶
df.shape
(365, 10)
It will be useful to have a variable (more accurately, an object ) that holds the value of the number of rows, and another for the number of columns.¶
Remember that Python is a language that uses zero-based indexing, so the first value is accessed as element 0, and the second as element 1!¶
Look at the syntax we use below to print out the (integer) value of nRows … it’s another example of string formating.¶
nRows = df.shape[0]
print ("Number of rows = %d" % nRows )
Number of rows = 365
Let’s do the same for the # of columns.¶
nCols = df.shape[1]
print ("Number of columns = %d" % nCols)
Number of columns = 10
To access the values in a particular column, we reference it with its column name as a string. The next cell pulls in all values of the year-month-date column, and assigns it to an object of the same name. We could have named the object anything we wanted, not just Date … but on the right side of the assignment statement, we have to use the exact name of the column.¶
Print out what this object looks like.
Date = df['DATE']
print (Date)
0 2022-01-01
1 2022-01-02
2 2022-01-03
3 2022-01-04
4 2022-01-05
...
360 2022-12-27
361 2022-12-28
362 2022-12-29
363 2022-12-30
364 2022-12-31
Name: DATE, Length: 365, dtype: string
Each column of a Pandas dataframe is known as a series. It is basically an array of values, each of which has a corresponding row #. By default, row #’s accompanying a Series are numbered consecutively, starting with 0 (since Python’s convention is to use zero-based indexing ).¶
We can reference a particular value, or set of values, of a Series by using array-based notation. Below, let’s print out the first 30 rows of the dates.¶
print (Date[:30])
0 2022-01-01
1 2022-01-02
2 2022-01-03
3 2022-01-04
4 2022-01-05
5 2022-01-06
6 2022-01-07
7 2022-01-08
8 2022-01-09
9 2022-01-10
10 2022-01-11
11 2022-01-12
12 2022-01-13
13 2022-01-14
14 2022-01-15
15 2022-01-16
16 2022-01-17
17 2022-01-18
18 2022-01-19
19 2022-01-20
20 2022-01-21
21 2022-01-22
22 2022-01-23
23 2022-01-24
24 2022-01-25
25 2022-01-26
26 2022-01-27
27 2022-01-28
28 2022-01-29
29 2022-01-30
Name: DATE, dtype: string
Similarly, let’s print out the last, or 364th row (Why is it 364, not 365???)¶
print(Date[364])
2022-12-31
Note that using -1 as the last index doesn’t work!
print(Date[-1])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/indexes/range.py:385, in RangeIndex.get_loc(self, key, method, tolerance)
384 try:
--> 385 return self._range.index(new_key)
386 except ValueError as err:
ValueError: -1 is not in range
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
Input In [11], in <cell line: 1>()
----> 1 print(Date[-1])
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/series.py:958, in Series.__getitem__(self, key)
955 return self._values[key]
957 elif key_is_scalar:
--> 958 return self._get_value(key)
960 if is_hashable(key):
961 # Otherwise index.get_value will raise InvalidIndexError
962 try:
963 # For labels that don't resolve as scalars like tuples and frozensets
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/series.py:1069, in Series._get_value(self, label, takeable)
1066 return self._values[label]
1068 # Similar to Index.get_value, but we do not fall back to positional
-> 1069 loc = self.index.get_loc(label)
1070 return self.index._get_values_for_loc(self, loc, label)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/indexes/range.py:387, in RangeIndex.get_loc(self, key, method, tolerance)
385 return self._range.index(new_key)
386 except ValueError as err:
--> 387 raise KeyError(key) from err
388 self._check_indexing_error(key)
389 raise KeyError(key)
KeyError: -1
However, using a negative value as part of a slice does work:
print(Date[-9:])
356 2022-12-23
357 2022-12-24
358 2022-12-25
359 2022-12-26
360 2022-12-27
361 2022-12-28
362 2022-12-29
363 2022-12-30
364 2022-12-31
Name: DATE, dtype: string
EXERCISE: Now, let’s create new Series objects; one for Max Temp (name it maxT), and the other for Min Temp (name it minT).¶
# %load /spare11/atm350/common/feb21/01a.py
maxT = df['MAX']
minT = df['MIN']
maxT
0 51
1 49
2 23
3 29
4 38
..
360 34
361 41
362 48
363 57
364 53
Name: MAX, Length: 365, dtype: string
minT
0 41
1 23
2 13
3 10
4 28
..
360 22
361 22
362 22
363 43
364 44
Name: MIN, Length: 365, dtype: string
Let’s now list all the days that the high temperature was >= 90. Note carefully how we express this test. It will fail!¶
hotDays = maxT >= 90
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [16], in <cell line: 1>()
----> 1 hotDays = maxT >= 90
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/ops/common.py:70, in _unpack_zerodim_and_defer.<locals>.new_method(self, other)
66 return NotImplemented
68 other = item_from_zerodim(other)
---> 70 return method(self, other)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/arraylike.py:60, in OpsMixin.__ge__(self, other)
58 @unpack_zerodim_and_defer("__ge__")
59 def __ge__(self, other):
---> 60 return self._cmp_method(other, operator.ge)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/series.py:5623, in Series._cmp_method(self, other, op)
5620 rvalues = extract_array(other, extract_numpy=True, extract_range=True)
5622 with np.errstate(all="ignore"):
-> 5623 res_values = ops.comparison_op(lvalues, rvalues, op)
5625 return self._construct_result(res_values, name=res_name)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/ops/array_ops.py:269, in comparison_op(left, right, op)
260 raise ValueError(
261 "Lengths must match to compare", lvalues.shape, rvalues.shape
262 )
264 if should_extension_dispatch(lvalues, rvalues) or (
265 (isinstance(rvalues, (Timedelta, BaseOffset, Timestamp)) or right is NaT)
266 and not is_object_dtype(lvalues.dtype)
267 ):
268 # Call the method on lvalues
--> 269 res_values = op(lvalues, rvalues)
271 elif is_scalar(rvalues) and isna(rvalues): # TODO: but not pd.NA?
272 # numpy does not like comparisons vs None
273 if op is operator.ne:
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/ops/common.py:70, in _unpack_zerodim_and_defer.<locals>.new_method(self, other)
66 return NotImplemented
68 other = item_from_zerodim(other)
---> 70 return method(self, other)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/arraylike.py:60, in OpsMixin.__ge__(self, other)
58 @unpack_zerodim_and_defer("__ge__")
59 def __ge__(self, other):
---> 60 return self._cmp_method(other, operator.ge)
File /knight/anaconda_aug22/envs/aug22_env/lib/python3.10/site-packages/pandas/core/arrays/string_.py:510, in StringArray._cmp_method(self, other, op)
507 else:
508 # logical
509 result = np.zeros(len(self._ndarray), dtype="bool")
--> 510 result[valid] = op(self._ndarray[valid], other)
511 return BooleanArray(result, mask)
TypeError: '>=' not supported between instances of 'str' and 'int'
Why did it fail? Remember, when we read in the file, we had Pandas assign the type of every column to string! We need to change the type of maxT to a numerical value. Let’s use a 32-bit floating point #, as that will be more than enough precision for this type of measurement. We’ll do the same for the minimum temp.¶
maxT = maxT.astype("float32")
minT = minT.astype("float32")
maxT
0 51.0
1 49.0
2 23.0
3 29.0
4 38.0
...
360 34.0
361 41.0
362 48.0
363 57.0
364 53.0
Name: MAX, Length: 365, dtype: float32
hotDays = maxT >= 90
Now, the test works. What does this data series look like? It actually is a table of booleans … i.e., true/false values.¶
print (hotDays)
0 False
1 False
2 False
3 False
4 False
...
360 False
361 False
362 False
363 False
364 False
Name: MAX, Length: 365, dtype: bool
As the default output only includes the first and last 5 rows , let’s slice and pull out a period in the middle of the year, where we might be more likely to get some Trues!¶
print (hotDays[180:195])
180 False
181 True
182 False
183 False
184 False
185 False
186 False
187 False
188 False
189 False
190 False
191 True
192 True
193 False
194 False
Name: MAX, dtype: bool
Now, let’s get a count of the # of days meeting this temperature criterion. Note carefully that we first have to express our set of days exceeding the threshold as a Pandas series. Then, recall that to get a count of the # of rows, we take the first (0th) element of the array returned by a call to the shape method.¶
df[maxT >= 90]
| DATE | MAX | MIN | AVG | DEP | HDD | CDD | PCP | SNW | DPT | |
|---|---|---|---|---|---|---|---|---|---|---|
| 140 | 2022-05-21 | 91 | 65 | 78.0 | 16.8 | 0 | 13 | 0.00 | 0.0 | 0 |
| 141 | 2022-05-22 | 90 | 59 | 74.5 | 13.0 | 0 | 10 | 0.09 | 0.0 | 0 |
| 150 | 2022-05-31 | 92 | 65 | 78.5 | 14.4 | 0 | 14 | 0.00 | 0.0 | 0 |
| 175 | 2022-06-25 | 91 | 58 | 74.5 | 3.6 | 0 | 10 | 0.00 | 0.0 | 0 |
| 176 | 2022-06-26 | 93 | 61 | 77.0 | 5.8 | 0 | 12 | 0.00 | 0.0 | 0 |
| 181 | 2022-07-01 | 95 | 68 | 81.5 | 9.4 | 0 | 17 | 0.13 | 0.0 | 0 |
| 191 | 2022-07-11 | 91 | 55 | 73.0 | -0.3 | 0 | 8 | 0.00 | 0.0 | 0 |
| 192 | 2022-07-12 | 91 | 70 | 80.5 | 7.2 | 0 | 16 | T | 0.0 | 0 |
| 197 | 2022-07-17 | 92 | 67 | 79.5 | 6.0 | 0 | 15 | 0.00 | 0.0 | 0 |
| 199 | 2022-07-19 | 92 | 71 | 81.5 | 8.0 | 0 | 17 | 0.00 | 0.0 | 0 |
| 200 | 2022-07-20 | 97 | 72 | 84.5 | 11.0 | 0 | 20 | 0.03 | 0.0 | 0 |
| 201 | 2022-07-21 | 96 | 72 | 84.0 | 10.5 | 0 | 19 | 0.00 | 0.0 | 0 |
| 202 | 2022-07-22 | 93 | 68 | 80.5 | 7.1 | 0 | 16 | 0.01 | 0.0 | 0 |
| 203 | 2022-07-23 | 97 | 65 | 81.0 | 7.6 | 0 | 16 | 0.00 | 0.0 | 0 |
| 204 | 2022-07-24 | 97 | 69 | 83.0 | 9.6 | 0 | 18 | 0.07 | 0.0 | 0 |
| 208 | 2022-07-28 | 92 | 67 | 79.5 | 6.3 | 0 | 15 | T | 0.0 | 0 |
| 214 | 2022-08-03 | 90 | 64 | 77.0 | 4.2 | 0 | 12 | 0.00 | 0.0 | 0 |
| 215 | 2022-08-04 | 99 | 72 | 85.5 | 12.7 | 0 | 21 | 0.74 | 0.0 | 0 |
| 216 | 2022-08-05 | 93 | 71 | 82.0 | 9.3 | 0 | 17 | T | 0.0 | 0 |
| 217 | 2022-08-06 | 93 | 70 | 81.5 | 8.9 | 0 | 17 | 0.51 | 0.0 | 0 |
| 218 | 2022-08-07 | 91 | 76 | 83.5 | 11.0 | 0 | 19 | 0.40 | 0.0 | 0 |
| 219 | 2022-08-08 | 95 | 75 | 85.0 | 12.6 | 0 | 20 | 0.08 | 0.0 | 0 |
| 231 | 2022-08-20 | 93 | 63 | 78.0 | 7.0 | 0 | 13 | 0.00 | 0.0 | 0 |
| 240 | 2022-08-29 | 91 | 69 | 80.0 | 10.7 | 0 | 15 | 0.00 | 0.0 | 0 |
| 241 | 2022-08-30 | 90 | 66 | 78.0 | 8.9 | 0 | 13 | 0.76 | 0.0 | 0 |
df[maxT >= 90].shape[0]
25
Let’s reverse the sense of the test, and get its count. The two counts should add up to 365!¶
df[maxT < 90].shape[0]
340
We can combine a test of two different thresholds. Let’s get a count of days where the max. temperature was in the 70s or 80s.¶
df[(maxT< 90) & (maxT>=70)].shape[0]
118
Let’s show all the climate data for all these “pleasantly warm” days!¶
pleasant = df[(maxT< 90) & (maxT>=70)]
pleasant
| DATE | MAX | MIN | AVG | DEP | HDD | CDD | PCP | SNW | DPT | |
|---|---|---|---|---|---|---|---|---|---|---|
| 76 | 2022-03-18 | 71 | 43 | 57.0 | 20.7 | 8 | 0 | 0.00 | 0.0 | 0 |
| 102 | 2022-04-13 | 77 | 41 | 59.0 | 12.1 | 6 | 0 | T | 0.0 | 0 |
| 103 | 2022-04-14 | 82 | 45 | 63.5 | 16.1 | 1 | 0 | 0.01 | 0.0 | 0 |
| 113 | 2022-04-24 | 72 | 45 | 58.5 | 6.6 | 6 | 0 | T | 0.0 | 0 |
| 128 | 2022-05-09 | 75 | 35 | 55.0 | -2.6 | 10 | 0 | 0.00 | 0.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 298 | 2022-10-26 | 76 | 58 | 67.0 | 19.3 | 0 | 2 | 0.00 | 0.0 | 0 |
| 307 | 2022-11-04 | 71 | 46 | 58.5 | 14.0 | 6 | 0 | 0.00 | 0.0 | 0 |
| 308 | 2022-11-05 | 76 | 61 | 68.5 | 24.3 | 0 | 4 | 0.00 | 0.0 | 0 |
| 309 | 2022-11-06 | 72 | 67 | 69.5 | 25.7 | 0 | 5 | 0.00 | 0.0 | 0 |
| 315 | 2022-11-12 | 71 | 49 | 60.0 | 18.3 | 5 | 0 | 0.66 | 0.0 | 0 |
118 rows × 10 columns
Notice that after a certain point, not all the rows are displayed to the notebook. We can eliminate the limit of maximum rows and thus show all of the matching days.¶
pd.set_option ('display.max_rows', None)
pleasant
| DATE | MAX | MIN | AVG | DEP | HDD | CDD | PCP | SNW | DPT | |
|---|---|---|---|---|---|---|---|---|---|---|
| 76 | 2022-03-18 | 71 | 43 | 57.0 | 20.7 | 8 | 0 | 0.00 | 0.0 | 0 |
| 102 | 2022-04-13 | 77 | 41 | 59.0 | 12.1 | 6 | 0 | T | 0.0 | 0 |
| 103 | 2022-04-14 | 82 | 45 | 63.5 | 16.1 | 1 | 0 | 0.01 | 0.0 | 0 |
| 113 | 2022-04-24 | 72 | 45 | 58.5 | 6.6 | 6 | 0 | T | 0.0 | 0 |
| 128 | 2022-05-09 | 75 | 35 | 55.0 | -2.6 | 10 | 0 | 0.00 | 0.0 | 0 |
| 129 | 2022-05-10 | 77 | 39 | 58.0 | 0.1 | 7 | 0 | 0.00 | 0.0 | 0 |
| 130 | 2022-05-11 | 82 | 40 | 61.0 | 2.8 | 4 | 0 | 0.00 | 0.0 | 0 |
| 131 | 2022-05-12 | 87 | 44 | 65.5 | 6.9 | 0 | 1 | 0.00 | 0.0 | 0 |
| 132 | 2022-05-13 | 84 | 62 | 73.0 | 14.1 | 0 | 8 | 0.00 | 0.0 | 0 |
| 133 | 2022-05-14 | 84 | 66 | 75.0 | 15.8 | 0 | 10 | 0.07 | 0.0 | 0 |
| 134 | 2022-05-15 | 82 | 64 | 73.0 | 13.5 | 0 | 8 | 0.28 | 0.0 | 0 |
| 135 | 2022-05-16 | 82 | 57 | 69.5 | 9.7 | 0 | 5 | 0.49 | 0.0 | 0 |
| 139 | 2022-05-20 | 79 | 46 | 62.5 | 1.5 | 2 | 0 | 0.00 | 0.0 | 0 |
| 143 | 2022-05-24 | 72 | 50 | 61.0 | -1.1 | 4 | 0 | 0.00 | 0.0 | 0 |
| 144 | 2022-05-25 | 77 | 55 | 66.0 | 3.6 | 0 | 1 | 0.00 | 0.0 | 0 |
| 145 | 2022-05-26 | 74 | 57 | 65.5 | 2.8 | 0 | 1 | 0.00 | 0.0 | 0 |
| 146 | 2022-05-27 | 77 | 63 | 70.0 | 7.1 | 0 | 5 | 0.00 | 0.0 | 0 |
| 147 | 2022-05-28 | 80 | 56 | 68.0 | 4.8 | 0 | 3 | 0.04 | 0.0 | 0 |
| 148 | 2022-05-29 | 80 | 51 | 65.5 | 2.0 | 0 | 1 | 0.00 | 0.0 | 0 |
| 149 | 2022-05-30 | 88 | 55 | 71.5 | 7.7 | 0 | 7 | 0.00 | 0.0 | 0 |
| 152 | 2022-06-02 | 78 | 63 | 70.5 | 5.9 | 0 | 6 | 0.00 | 0.0 | 0 |
| 153 | 2022-06-03 | 78 | 58 | 68.0 | 3.1 | 0 | 3 | T | 0.0 | 0 |
| 154 | 2022-06-04 | 78 | 49 | 63.5 | -1.7 | 1 | 0 | 0.00 | 0.0 | 0 |
| 155 | 2022-06-05 | 77 | 47 | 62.0 | -3.5 | 3 | 0 | 0.00 | 0.0 | 0 |
| 156 | 2022-06-06 | 81 | 51 | 66.0 | 0.2 | 0 | 1 | 0.00 | 0.0 | 0 |
| 157 | 2022-06-07 | 80 | 65 | 72.5 | 6.4 | 0 | 8 | 0.08 | 0.0 | 0 |
| 158 | 2022-06-08 | 77 | 61 | 69.0 | 2.6 | 0 | 4 | 0.26 | 0.0 | 0 |
| 159 | 2022-06-09 | 75 | 58 | 66.5 | -0.2 | 0 | 2 | 0.75 | 0.0 | 0 |
| 160 | 2022-06-10 | 76 | 53 | 64.5 | -2.5 | 0 | 0 | 0.00 | 0.0 | 0 |
| 161 | 2022-06-11 | 78 | 50 | 64.0 | -3.3 | 1 | 0 | 0.00 | 0.0 | 0 |
| 162 | 2022-06-12 | 78 | 55 | 66.5 | -1.0 | 0 | 2 | 0.01 | 0.0 | 0 |
| 163 | 2022-06-13 | 82 | 60 | 71.0 | 3.2 | 0 | 6 | 0.00 | 0.0 | 0 |
| 164 | 2022-06-14 | 83 | 53 | 68.0 | -0.1 | 0 | 3 | 0.00 | 0.0 | 0 |
| 165 | 2022-06-15 | 84 | 57 | 70.5 | 2.1 | 0 | 6 | 0.00 | 0.0 | 0 |
| 166 | 2022-06-16 | 75 | 66 | 70.5 | 1.8 | 0 | 6 | T | 0.0 | 0 |
| 167 | 2022-06-17 | 86 | 67 | 76.5 | 7.6 | 0 | 12 | 0.00 | 0.0 | 0 |
| 169 | 2022-06-19 | 73 | 50 | 61.5 | -8.0 | 3 | 0 | 0.00 | 0.0 | 0 |
| 170 | 2022-06-20 | 82 | 47 | 64.5 | -5.2 | 0 | 0 | 0.00 | 0.0 | 0 |
| 171 | 2022-06-21 | 70 | 51 | 60.5 | -9.5 | 4 | 0 | 0.05 | 0.0 | 0 |
| 173 | 2022-06-23 | 73 | 60 | 66.5 | -4.0 | 0 | 2 | 0.02 | 0.0 | 0 |
| 174 | 2022-06-24 | 86 | 61 | 73.5 | 2.8 | 0 | 9 | 0.00 | 0.0 | 0 |
| 177 | 2022-06-27 | 80 | 61 | 70.5 | -0.9 | 0 | 6 | 0.30 | 0.0 | 0 |
| 178 | 2022-06-28 | 79 | 55 | 67.0 | -4.6 | 0 | 2 | 0.00 | 0.0 | 0 |
| 179 | 2022-06-29 | 85 | 53 | 69.0 | -2.8 | 0 | 4 | 0.00 | 0.0 | 0 |
| 180 | 2022-06-30 | 85 | 56 | 70.5 | -1.5 | 0 | 6 | 0.00 | 0.0 | 0 |
| 182 | 2022-07-02 | 87 | 62 | 74.5 | 2.2 | 0 | 10 | 0.07 | 0.0 | 0 |
| 183 | 2022-07-03 | 83 | 59 | 71.0 | -1.4 | 0 | 6 | 0.00 | 0.0 | 0 |
| 184 | 2022-07-04 | 84 | 54 | 69.0 | -3.6 | 0 | 4 | 0.00 | 0.0 | 0 |
| 185 | 2022-07-05 | 74 | 65 | 69.5 | -3.2 | 0 | 5 | 0.35 | 0.0 | 0 |
| 186 | 2022-07-06 | 81 | 63 | 72.0 | -0.8 | 0 | 7 | 0.02 | 0.0 | 0 |
| 187 | 2022-07-07 | 85 | 58 | 71.5 | -1.4 | 0 | 7 | 0.00 | 0.0 | 0 |
| 188 | 2022-07-08 | 85 | 67 | 76.0 | 3.0 | 0 | 11 | 0.00 | 0.0 | 0 |
| 189 | 2022-07-09 | 80 | 61 | 70.5 | -2.6 | 0 | 6 | 0.00 | 0.0 | 0 |
| 190 | 2022-07-10 | 81 | 52 | 66.5 | -6.7 | 0 | 2 | 0.00 | 0.0 | 0 |
| 193 | 2022-07-13 | 87 | 62 | 74.5 | 1.1 | 0 | 10 | T | 0.0 | 0 |
| 194 | 2022-07-14 | 85 | 65 | 75.0 | 1.6 | 0 | 10 | 0.00 | 0.0 | 0 |
| 195 | 2022-07-15 | 86 | 57 | 71.5 | -1.9 | 0 | 7 | 0.00 | 0.0 | 0 |
| 196 | 2022-07-16 | 88 | 60 | 74.0 | 0.5 | 0 | 9 | T | 0.0 | 0 |
| 198 | 2022-07-18 | 81 | 73 | 77.0 | 3.5 | 0 | 12 | 0.16 | 0.0 | 0 |
| 205 | 2022-07-25 | 88 | 65 | 76.5 | 3.1 | 0 | 12 | 0.60 | 0.0 | 0 |
| 206 | 2022-07-26 | 80 | 61 | 70.5 | -2.8 | 0 | 6 | 0.00 | 0.0 | 0 |
| 207 | 2022-07-27 | 83 | 57 | 70.0 | -3.3 | 0 | 5 | 0.00 | 0.0 | 0 |
| 209 | 2022-07-29 | 89 | 68 | 78.5 | 5.3 | 0 | 14 | 0.01 | 0.0 | 0 |
| 210 | 2022-07-30 | 82 | 64 | 73.0 | -0.1 | 0 | 8 | 0.00 | 0.0 | 0 |
| 211 | 2022-07-31 | 86 | 60 | 73.0 | 0.0 | 0 | 8 | 0.00 | 0.0 | 0 |
| 212 | 2022-08-01 | 89 | 69 | 79.0 | 6.0 | 0 | 14 | 0.00 | 0.0 | 0 |
| 213 | 2022-08-02 | 89 | 70 | 79.5 | 6.6 | 0 | 15 | 0.00 | 0.0 | 0 |
| 220 | 2022-08-09 | 86 | 67 | 76.5 | 4.2 | 0 | 12 | 0.07 | 0.0 | 0 |
| 221 | 2022-08-10 | 79 | 63 | 71.0 | -1.2 | 0 | 6 | 0.00 | 0.0 | 0 |
| 222 | 2022-08-11 | 85 | 63 | 74.0 | 1.9 | 0 | 9 | 0.00 | 0.0 | 0 |
| 223 | 2022-08-12 | 79 | 60 | 69.5 | -2.5 | 0 | 5 | 0.00 | 0.0 | 0 |
| 224 | 2022-08-13 | 79 | 59 | 69.0 | -2.9 | 0 | 4 | 0.00 | 0.0 | 0 |
| 225 | 2022-08-14 | 82 | 54 | 68.0 | -3.8 | 0 | 3 | 0.00 | 0.0 | 0 |
| 226 | 2022-08-15 | 87 | 58 | 72.5 | 0.8 | 0 | 8 | 0.00 | 0.0 | 0 |
| 227 | 2022-08-16 | 87 | 58 | 72.5 | 0.9 | 0 | 8 | T | 0.0 | 0 |
| 228 | 2022-08-17 | 78 | 62 | 70.0 | -1.5 | 0 | 5 | 0.76 | 0.0 | 0 |
| 229 | 2022-08-18 | 81 | 61 | 71.0 | -0.3 | 0 | 6 | 0.00 | 0.0 | 0 |
| 230 | 2022-08-19 | 89 | 58 | 73.5 | 2.3 | 0 | 9 | 0.00 | 0.0 | 0 |
| 232 | 2022-08-21 | 88 | 70 | 79.0 | 8.1 | 0 | 14 | 0.00 | 0.0 | 0 |
| 233 | 2022-08-22 | 81 | 70 | 75.5 | 4.8 | 0 | 11 | T | 0.0 | 0 |
| 234 | 2022-08-23 | 80 | 68 | 74.0 | 3.4 | 0 | 9 | 0.47 | 0.0 | 0 |
| 235 | 2022-08-24 | 86 | 66 | 76.0 | 5.6 | 0 | 11 | 0.00 | 0.0 | 0 |
| 236 | 2022-08-25 | 87 | 60 | 73.5 | 3.3 | 0 | 9 | 0.02 | 0.0 | 0 |
| 237 | 2022-08-26 | 83 | 62 | 72.5 | 2.5 | 0 | 8 | 0.03 | 0.0 | 0 |
| 238 | 2022-08-27 | 81 | 64 | 72.5 | 2.7 | 0 | 8 | 0.00 | 0.0 | 0 |
| 239 | 2022-08-28 | 83 | 59 | 71.0 | 1.4 | 0 | 6 | 0.00 | 0.0 | 0 |
| 242 | 2022-08-31 | 79 | 66 | 72.5 | 3.7 | 0 | 8 | T | 0.0 | 0 |
| 243 | 2022-09-01 | 73 | 55 | 64.0 | -4.6 | 1 | 0 | 0.01 | 0.0 | 0 |
| 244 | 2022-09-02 | 80 | 48 | 64.0 | -4.3 | 1 | 0 | 0.00 | 0.0 | 0 |
| 245 | 2022-09-03 | 83 | 56 | 69.5 | 1.5 | 0 | 5 | 0.00 | 0.0 | 0 |
| 246 | 2022-09-04 | 87 | 61 | 74.0 | 6.3 | 0 | 9 | 0.01 | 0.0 | 0 |
| 249 | 2022-09-07 | 72 | 59 | 65.5 | -1.3 | 0 | 1 | 0.00 | 0.0 | 0 |
| 250 | 2022-09-08 | 80 | 58 | 69.0 | 2.5 | 0 | 4 | 0.00 | 0.0 | 0 |
| 251 | 2022-09-09 | 83 | 55 | 69.0 | 2.9 | 0 | 4 | 0.00 | 0.0 | 0 |
| 252 | 2022-09-10 | 83 | 56 | 69.5 | 3.7 | 0 | 5 | 0.00 | 0.0 | 0 |
| 253 | 2022-09-11 | 74 | 64 | 69.0 | 3.6 | 0 | 4 | 0.02 | 0.0 | 0 |
| 254 | 2022-09-12 | 80 | 65 | 72.5 | 7.4 | 0 | 8 | T | 0.0 | 0 |
| 255 | 2022-09-13 | 79 | 58 | 68.5 | 3.8 | 0 | 4 | 1.57 | 0.0 | 0 |
| 256 | 2022-09-14 | 79 | 57 | 68.0 | 3.7 | 0 | 3 | 0.00 | 0.0 | 0 |
| 257 | 2022-09-15 | 70 | 51 | 60.5 | -3.4 | 4 | 0 | 0.00 | 0.0 | 0 |
| 258 | 2022-09-16 | 71 | 45 | 58.0 | -5.5 | 7 | 0 | 0.00 | 0.0 | 0 |
| 259 | 2022-09-17 | 72 | 51 | 61.5 | -1.6 | 3 | 0 | 0.00 | 0.0 | 0 |
| 260 | 2022-09-18 | 80 | 62 | 71.0 | 8.3 | 0 | 6 | 0.44 | 0.0 | 0 |
| 261 | 2022-09-19 | 81 | 63 | 72.0 | 9.7 | 0 | 7 | 0.34 | 0.0 | 0 |
| 262 | 2022-09-20 | 75 | 59 | 67.0 | 5.1 | 0 | 2 | T | 0.0 | 0 |
| 263 | 2022-09-21 | 76 | 57 | 66.5 | 5.0 | 0 | 2 | 0.00 | 0.0 | 0 |
| 264 | 2022-09-22 | 71 | 51 | 61.0 | 0.0 | 4 | 0 | 0.64 | 0.0 | 0 |
| 268 | 2022-09-26 | 71 | 53 | 62.0 | 2.7 | 3 | 0 | 0.23 | 0.0 | 0 |
| 278 | 2022-10-06 | 75 | 42 | 58.5 | 3.4 | 6 | 0 | 0.00 | 0.0 | 0 |
| 279 | 2022-10-07 | 71 | 48 | 59.5 | 4.8 | 5 | 0 | 0.02 | 0.0 | 0 |
| 284 | 2022-10-12 | 71 | 41 | 56.0 | 3.3 | 9 | 0 | 0.00 | 0.0 | 0 |
| 285 | 2022-10-13 | 70 | 53 | 61.5 | 9.1 | 3 | 0 | 1.21 | 0.0 | 0 |
| 297 | 2022-10-25 | 73 | 58 | 65.5 | 17.5 | 0 | 1 | 0.25 | 0.0 | 0 |
| 298 | 2022-10-26 | 76 | 58 | 67.0 | 19.3 | 0 | 2 | 0.00 | 0.0 | 0 |
| 307 | 2022-11-04 | 71 | 46 | 58.5 | 14.0 | 6 | 0 | 0.00 | 0.0 | 0 |
| 308 | 2022-11-05 | 76 | 61 | 68.5 | 24.3 | 0 | 4 | 0.00 | 0.0 | 0 |
| 309 | 2022-11-06 | 72 | 67 | 69.5 | 25.7 | 0 | 5 | 0.00 | 0.0 | 0 |
| 315 | 2022-11-12 | 71 | 49 | 60.0 | 18.3 | 5 | 0 | 0.66 | 0.0 | 0 |
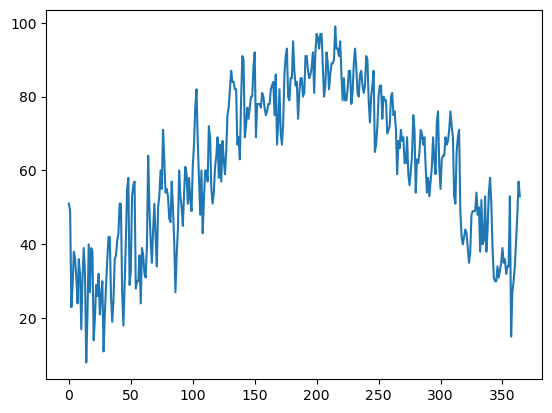
Now let’s visualize the temperature trace over the year! Pandas has a method that directly calls Matplotlib’s plotting package.¶
maxT.plot()
<AxesSubplot:>
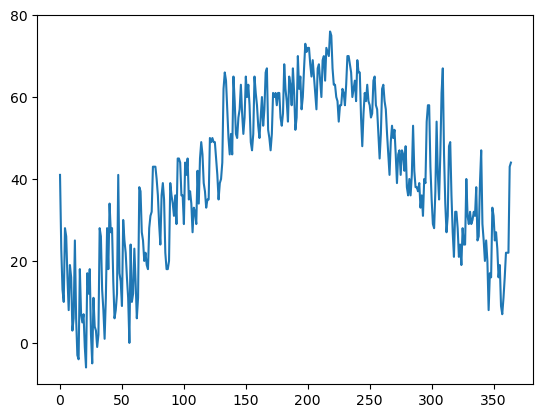
minT.plot()
<AxesSubplot:>
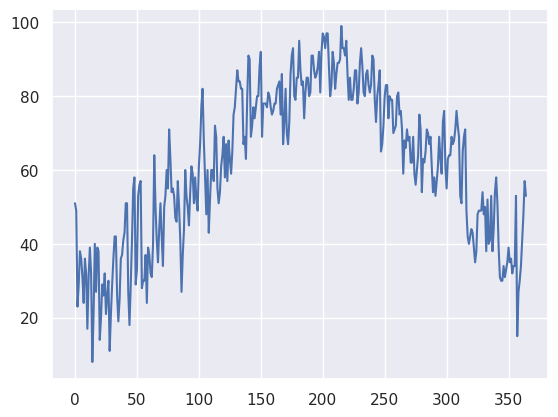
The data plotted fine, but the look could be better. First, let’s import a package, seaborn, that when imported and set using its own method, makes matplotlib’s graphs look better.¶
Info on seaborn: https://seaborn.pydata.org/index.html
import seaborn as sns
sns.set()
maxT.plot()
<AxesSubplot:>
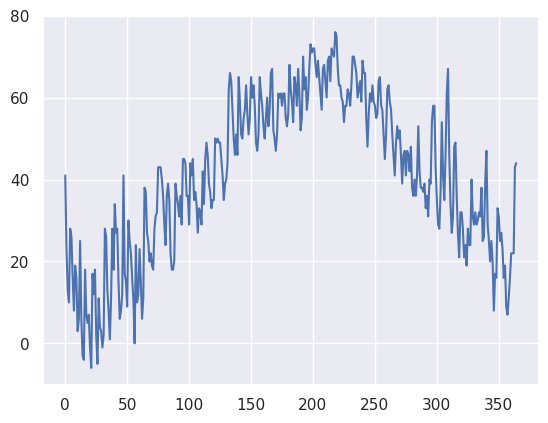
minT.plot()
<AxesSubplot:>
Next, let’s plot the two traces simultaneously on the graph so we can better discern max and min temps (this will also enure a single y-axis that will encompass the range of temperature values). We’ll also add some helpful labels and expand the size of the figure.¶
fig, ax = plt.subplots(figsize=(15,10))
ax.plot (Date, maxT, color='red')
ax.plot (Date, minT, color='blue')
ax.set_title ("ALB Year 2022")
ax.set_xlabel('Day of Year')
ax.set_ylabel('Temperature ($^\circ$F)')
Text(0, 0.5, 'Temperature ($^\\circ$F)')
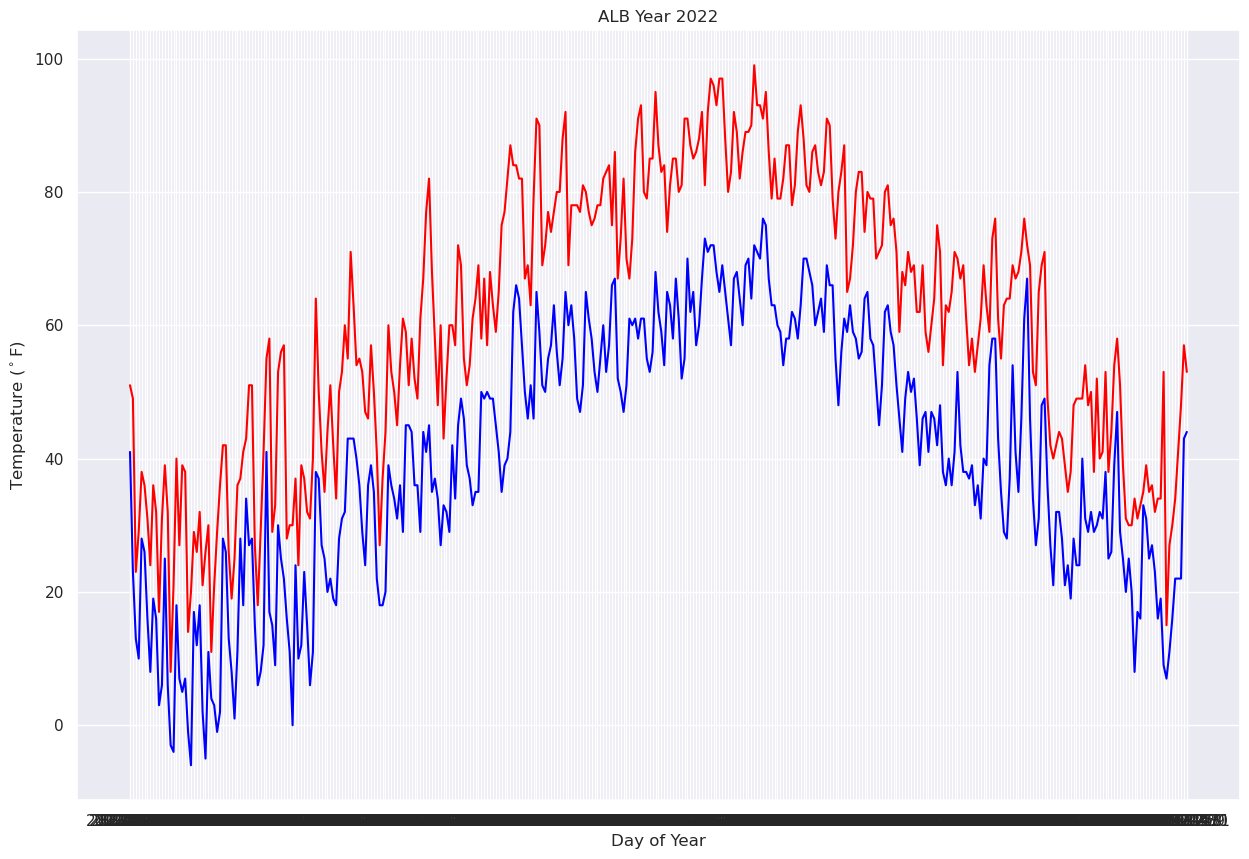
You will notice that this graphic took some time to render. Note that the x-axis label is virtually unreadable. This is because every date is being printed!¶
We will deal with this by using one of Pandas’ methods that take strings and convert them to a special type of data … not strings nor numbers, but datetime objects. Note carefully how we do this here … it is not terribly intuitive, but we’ll explain it more in an upcoming lecture/notebook on datetime. You will see though that the output column now looks a bit more date-like, with a four-digit year followed by two-digit month and date.¶
Date = pd.to_datetime(Date,format="%Y-%m-%d")
Date
0 2022-01-01
1 2022-01-02
2 2022-01-03
3 2022-01-04
4 2022-01-05
5 2022-01-06
6 2022-01-07
7 2022-01-08
8 2022-01-09
9 2022-01-10
10 2022-01-11
11 2022-01-12
12 2022-01-13
13 2022-01-14
14 2022-01-15
15 2022-01-16
16 2022-01-17
17 2022-01-18
18 2022-01-19
19 2022-01-20
20 2022-01-21
21 2022-01-22
22 2022-01-23
23 2022-01-24
24 2022-01-25
25 2022-01-26
26 2022-01-27
27 2022-01-28
28 2022-01-29
29 2022-01-30
30 2022-01-31
31 2022-02-01
32 2022-02-02
33 2022-02-03
34 2022-02-04
35 2022-02-05
36 2022-02-06
37 2022-02-07
38 2022-02-08
39 2022-02-09
40 2022-02-10
41 2022-02-11
42 2022-02-12
43 2022-02-13
44 2022-02-14
45 2022-02-15
46 2022-02-16
47 2022-02-17
48 2022-02-18
49 2022-02-19
50 2022-02-20
51 2022-02-21
52 2022-02-22
53 2022-02-23
54 2022-02-24
55 2022-02-25
56 2022-02-26
57 2022-02-27
58 2022-02-28
59 2022-03-01
60 2022-03-02
61 2022-03-03
62 2022-03-04
63 2022-03-05
64 2022-03-06
65 2022-03-07
66 2022-03-08
67 2022-03-09
68 2022-03-10
69 2022-03-11
70 2022-03-12
71 2022-03-13
72 2022-03-14
73 2022-03-15
74 2022-03-16
75 2022-03-17
76 2022-03-18
77 2022-03-19
78 2022-03-20
79 2022-03-21
80 2022-03-22
81 2022-03-23
82 2022-03-24
83 2022-03-25
84 2022-03-26
85 2022-03-27
86 2022-03-28
87 2022-03-29
88 2022-03-30
89 2022-03-31
90 2022-04-01
91 2022-04-02
92 2022-04-03
93 2022-04-04
94 2022-04-05
95 2022-04-06
96 2022-04-07
97 2022-04-08
98 2022-04-09
99 2022-04-10
100 2022-04-11
101 2022-04-12
102 2022-04-13
103 2022-04-14
104 2022-04-15
105 2022-04-16
106 2022-04-17
107 2022-04-18
108 2022-04-19
109 2022-04-20
110 2022-04-21
111 2022-04-22
112 2022-04-23
113 2022-04-24
114 2022-04-25
115 2022-04-26
116 2022-04-27
117 2022-04-28
118 2022-04-29
119 2022-04-30
120 2022-05-01
121 2022-05-02
122 2022-05-03
123 2022-05-04
124 2022-05-05
125 2022-05-06
126 2022-05-07
127 2022-05-08
128 2022-05-09
129 2022-05-10
130 2022-05-11
131 2022-05-12
132 2022-05-13
133 2022-05-14
134 2022-05-15
135 2022-05-16
136 2022-05-17
137 2022-05-18
138 2022-05-19
139 2022-05-20
140 2022-05-21
141 2022-05-22
142 2022-05-23
143 2022-05-24
144 2022-05-25
145 2022-05-26
146 2022-05-27
147 2022-05-28
148 2022-05-29
149 2022-05-30
150 2022-05-31
151 2022-06-01
152 2022-06-02
153 2022-06-03
154 2022-06-04
155 2022-06-05
156 2022-06-06
157 2022-06-07
158 2022-06-08
159 2022-06-09
160 2022-06-10
161 2022-06-11
162 2022-06-12
163 2022-06-13
164 2022-06-14
165 2022-06-15
166 2022-06-16
167 2022-06-17
168 2022-06-18
169 2022-06-19
170 2022-06-20
171 2022-06-21
172 2022-06-22
173 2022-06-23
174 2022-06-24
175 2022-06-25
176 2022-06-26
177 2022-06-27
178 2022-06-28
179 2022-06-29
180 2022-06-30
181 2022-07-01
182 2022-07-02
183 2022-07-03
184 2022-07-04
185 2022-07-05
186 2022-07-06
187 2022-07-07
188 2022-07-08
189 2022-07-09
190 2022-07-10
191 2022-07-11
192 2022-07-12
193 2022-07-13
194 2022-07-14
195 2022-07-15
196 2022-07-16
197 2022-07-17
198 2022-07-18
199 2022-07-19
200 2022-07-20
201 2022-07-21
202 2022-07-22
203 2022-07-23
204 2022-07-24
205 2022-07-25
206 2022-07-26
207 2022-07-27
208 2022-07-28
209 2022-07-29
210 2022-07-30
211 2022-07-31
212 2022-08-01
213 2022-08-02
214 2022-08-03
215 2022-08-04
216 2022-08-05
217 2022-08-06
218 2022-08-07
219 2022-08-08
220 2022-08-09
221 2022-08-10
222 2022-08-11
223 2022-08-12
224 2022-08-13
225 2022-08-14
226 2022-08-15
227 2022-08-16
228 2022-08-17
229 2022-08-18
230 2022-08-19
231 2022-08-20
232 2022-08-21
233 2022-08-22
234 2022-08-23
235 2022-08-24
236 2022-08-25
237 2022-08-26
238 2022-08-27
239 2022-08-28
240 2022-08-29
241 2022-08-30
242 2022-08-31
243 2022-09-01
244 2022-09-02
245 2022-09-03
246 2022-09-04
247 2022-09-05
248 2022-09-06
249 2022-09-07
250 2022-09-08
251 2022-09-09
252 2022-09-10
253 2022-09-11
254 2022-09-12
255 2022-09-13
256 2022-09-14
257 2022-09-15
258 2022-09-16
259 2022-09-17
260 2022-09-18
261 2022-09-19
262 2022-09-20
263 2022-09-21
264 2022-09-22
265 2022-09-23
266 2022-09-24
267 2022-09-25
268 2022-09-26
269 2022-09-27
270 2022-09-28
271 2022-09-29
272 2022-09-30
273 2022-10-01
274 2022-10-02
275 2022-10-03
276 2022-10-04
277 2022-10-05
278 2022-10-06
279 2022-10-07
280 2022-10-08
281 2022-10-09
282 2022-10-10
283 2022-10-11
284 2022-10-12
285 2022-10-13
286 2022-10-14
287 2022-10-15
288 2022-10-16
289 2022-10-17
290 2022-10-18
291 2022-10-19
292 2022-10-20
293 2022-10-21
294 2022-10-22
295 2022-10-23
296 2022-10-24
297 2022-10-25
298 2022-10-26
299 2022-10-27
300 2022-10-28
301 2022-10-29
302 2022-10-30
303 2022-10-31
304 2022-11-01
305 2022-11-02
306 2022-11-03
307 2022-11-04
308 2022-11-05
309 2022-11-06
310 2022-11-07
311 2022-11-08
312 2022-11-09
313 2022-11-10
314 2022-11-11
315 2022-11-12
316 2022-11-13
317 2022-11-14
318 2022-11-15
319 2022-11-16
320 2022-11-17
321 2022-11-18
322 2022-11-19
323 2022-11-20
324 2022-11-21
325 2022-11-22
326 2022-11-23
327 2022-11-24
328 2022-11-25
329 2022-11-26
330 2022-11-27
331 2022-11-28
332 2022-11-29
333 2022-11-30
334 2022-12-01
335 2022-12-02
336 2022-12-03
337 2022-12-04
338 2022-12-05
339 2022-12-06
340 2022-12-07
341 2022-12-08
342 2022-12-09
343 2022-12-10
344 2022-12-11
345 2022-12-12
346 2022-12-13
347 2022-12-14
348 2022-12-15
349 2022-12-16
350 2022-12-17
351 2022-12-18
352 2022-12-19
353 2022-12-20
354 2022-12-21
355 2022-12-22
356 2022-12-23
357 2022-12-24
358 2022-12-25
359 2022-12-26
360 2022-12-27
361 2022-12-28
362 2022-12-29
363 2022-12-30
364 2022-12-31
Name: DATE, dtype: datetime64[ns]
Matplotlib will recognize this array as being date/time-related, and when we pass it in as the x-axis, the graphic appears faster, and we also have a more meaningful x-axis label.¶
fig, ax = plt.subplots(figsize=(15,10))
ax.plot (Date, maxT, color='red')
ax.plot (Date, minT, color='blue')
ax.set_title ("ALB Year 2022")
ax.set_xlabel('Day of Year')
ax.set_ylabel('Temperature ($^\circ$F)');
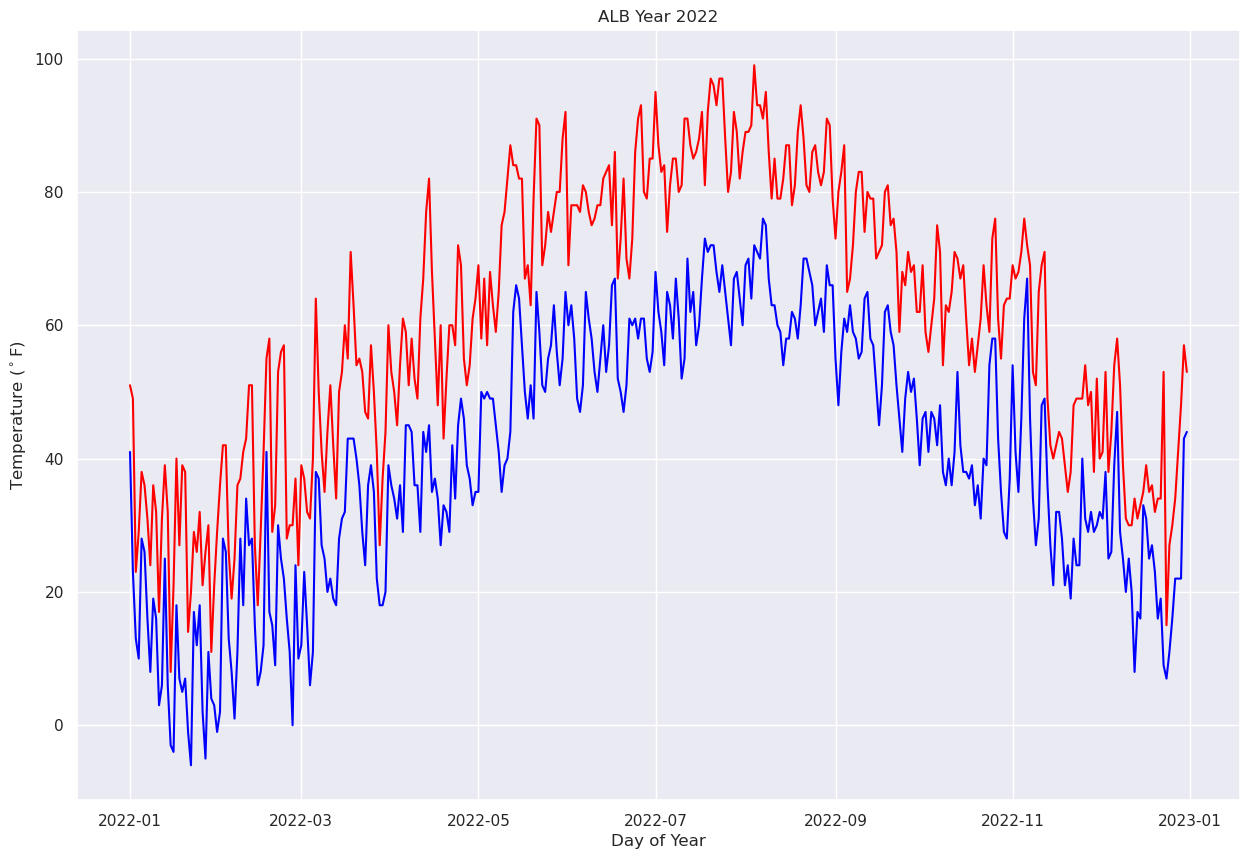
We’ll further refine the look of the plot by adding a legend and have vertical grid lines on a frequency of one month.¶
from matplotlib.dates import DateFormatter, AutoDateLocator,HourLocator,DayLocator,MonthLocator
fig, ax = plt.subplots(figsize=(15,10))
ax.plot (Date, maxT, color='red',label = "Max T")
ax.plot (Date, minT, color='blue', label = "Min T")
ax.set_title ("ALB Year 2022")
ax.set_xlabel('Date')
ax.set_ylabel('Temperature ($^\circ$F)' )
ax.xaxis.set_major_locator(MonthLocator(interval=1))
dateFmt = DateFormatter('%b %d')
ax.xaxis.set_major_formatter(dateFmt)
ax.legend (loc="best")
<matplotlib.legend.Legend at 0x154c35781b70>
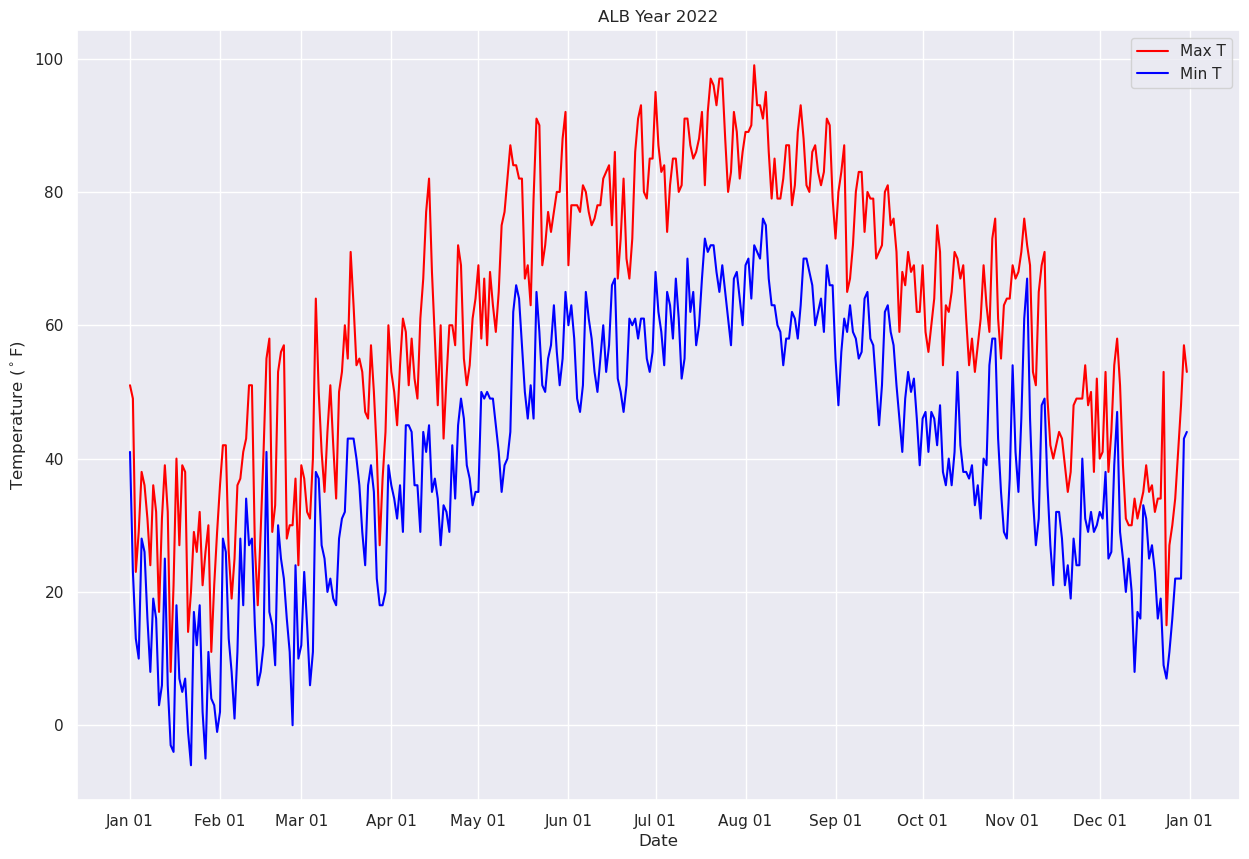
Let’s save our beautiful graphic to disk.¶
fig.savefig ('albTemps2022.png')
Now, let’s answer the question, “what was the most common range of maximum temperatures last year in Albany?” via a histogram. We use matplotlib’s hist method.¶
# Create a figure and size it.
fig, ax = plt.subplots(figsize=(15,10))
# Create a histogram of our data series and divide it in to 10 bins.
ax.hist(maxT, bins=10, color='k', alpha=0.3)
(array([ 5., 13., 37., 42., 38., 46., 52., 52., 55., 25.]),
array([ 8. , 17.1, 26.2, 35.3, 44.4, 53.5, 62.6, 71.7, 80.8, 89.9, 99. ],
dtype=float32),
<BarContainer object of 10 artists>)
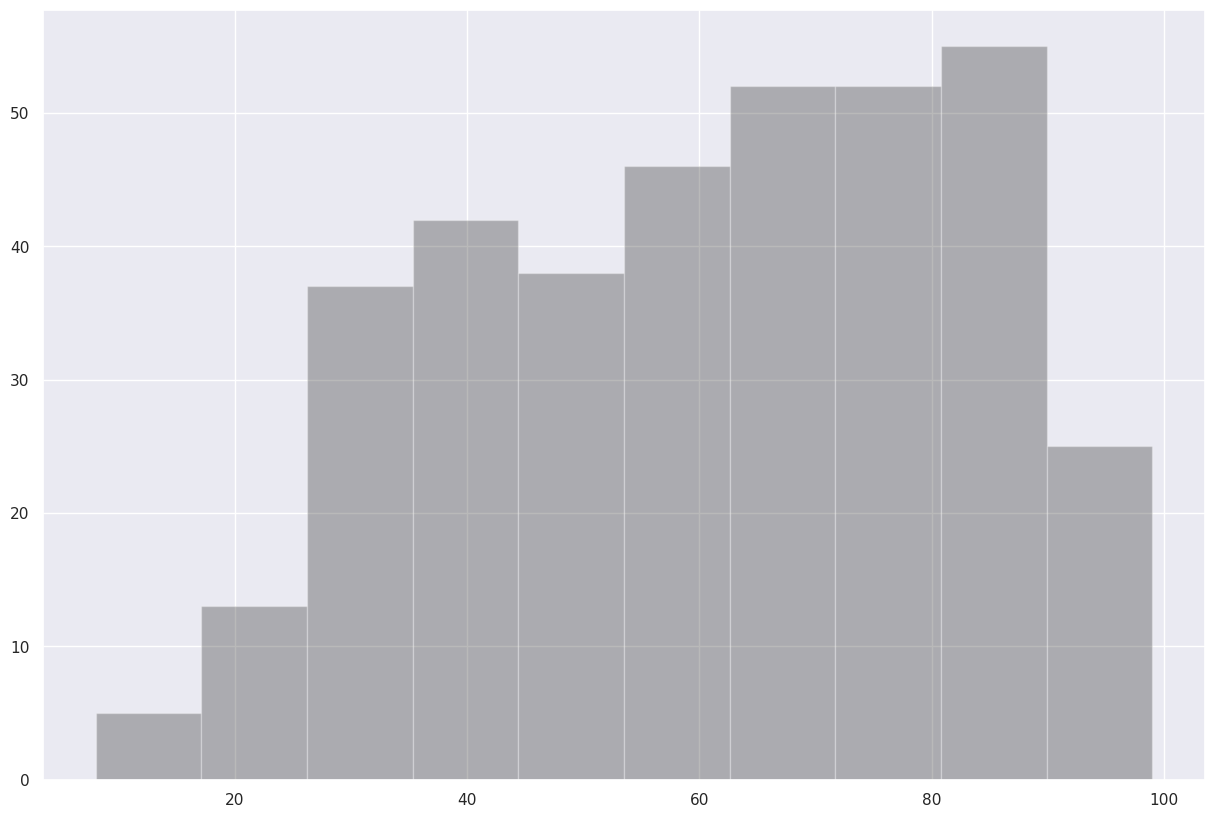
Ok, but the 10 bins were autoselected. Let’s customize our call to the hist method by specifying the bounds of each of our bins.¶
How can we learn more about how to customize this call? Append a ? to the name of the method.¶
ax.hist?
Revise the call to ax.hist, and also draw tick marks that align with the bounds of the histogram’s bins.¶
fig, ax = plt.subplots(figsize=(15,10))
ax.hist(maxT, bins=(0,10,20,30,40,50,60,70,80,90,100), color='k', alpha=0.3)
ax.xaxis.set_major_locator(plt.MultipleLocator(10))
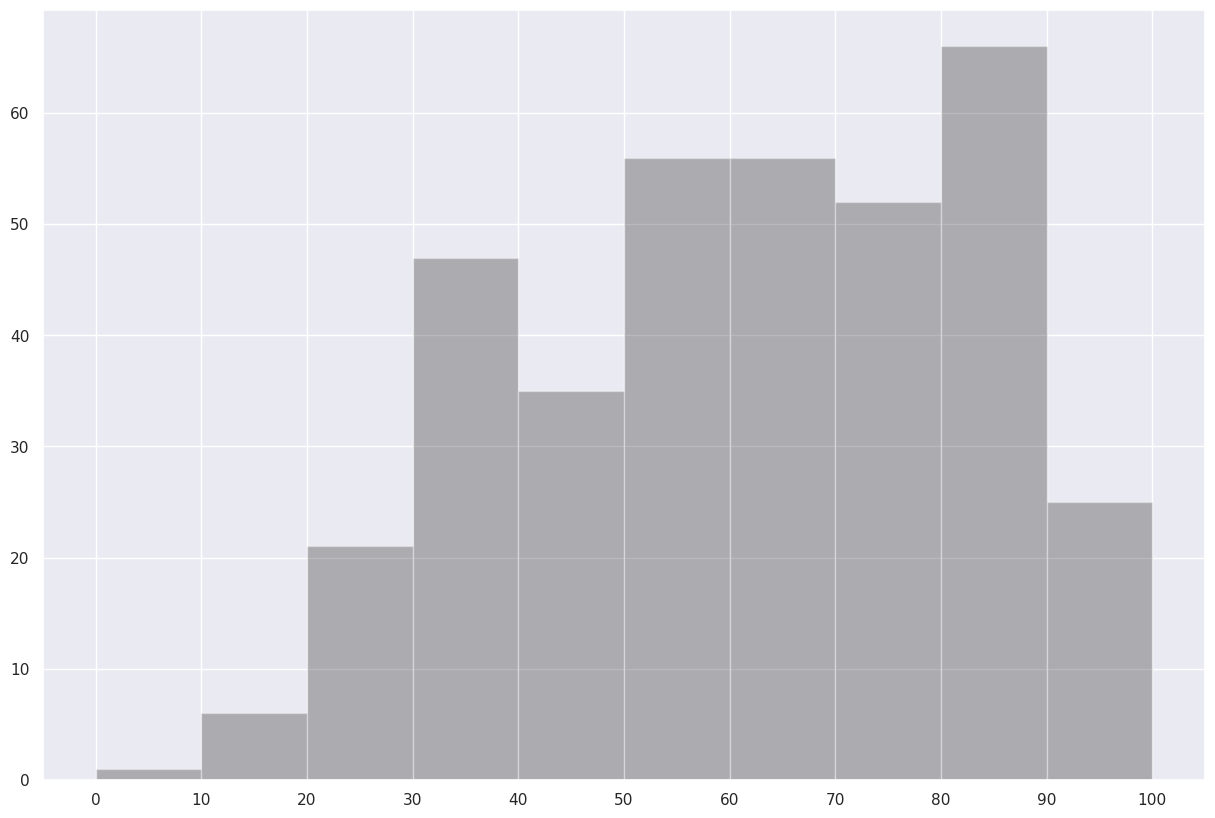
Save this histogram to disk.¶
fig.savefig("maxT_hist.png")
Use the describe method on the maximum temperature series to reveal some simple statistical properties.
maxT.describe()
count 365.000000
mean 60.915070
std 21.009434
min 8.000000
25% 43.000000
50% 63.000000
75% 79.000000
max 99.000000
Name: MAX, dtype: float64